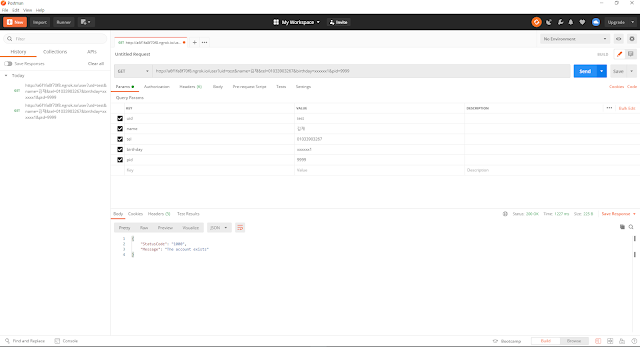
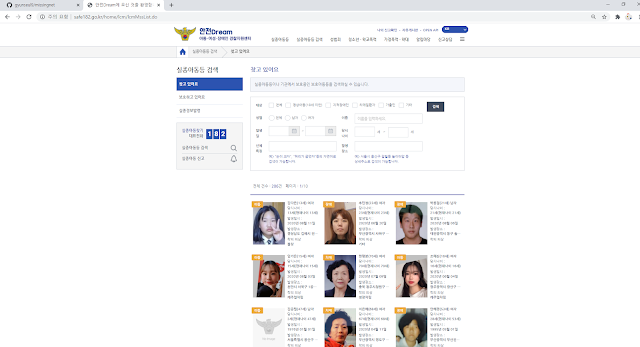
구름IDE로 Flask API 컨테이너 생성하는 방법입니다.

# Howto # Goormide # Create # Flask # Container # Convert # Google # Colaboratory 1. 컨테이너 생성 2.소프트웨어 스택 선택 → Flask 3.추가모듈/패키지 설치 4. 파이썬 소스 코드를 적용 5.터미널에서 Flask API 실행 참고로 추가모듈 MySQL을 설치 하지 않을 경우 pip3 install pymysql 명령어를 실행해도 오류가 발생합니다.